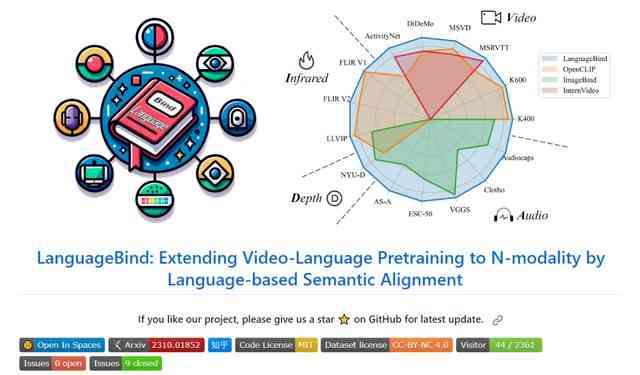
北京大学和腾讯等单位的研究者共同开发出了一种称为LanguageBind的多模态对齐框架。这个框架将语言作为纽带,通过构造一个包含多模态编码器、语言编码器和多模态联合学习三个部分的中心通道,实现了视频、音频、深度、红外等各模态与语言特征空间的精准对齐。这一框架摒弃了传统方法中依赖图像作为主导模态的方式,直接利用语言模态作为不同模态之间的连接。研究团队还为此框架构建了一个名为“VIDAL-10M”的高质量数据集,包含1000万对具有对齐视频-语言、红外-语言、深度-语言、音频-语言的数据,以确保跨模态信息的完整性和一致性。
测试阶段,LanguageBind在多个数据集上表现出色,力压ImageBind和OpenCLIP等竞争对手,性能在多个榜单上取得了领先。特别是在VIDAL-10M数据集上进行训练后,LanguageBind在15个广泛的基准测试中展现出卓越的性能。实验结果显示,LanguageBind在多个模态的零样本分类任务中实现了显著的性能提升,表明了它在理解和处理不同模态数据方面的强大潜力。该框架不仅适用于现有的模态,还能适应未来可能出现的新模态,为多模态预训练技术的发展奠定了坚实的基础。
